
简要说一下fork。
首先这个函数的名字就很形象很巧妙,fork是个叉子。
当时在看书的时候还是有些迷惑,也许是程序进程线程函数没分开吧[悲]。
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
#include<stdlib.h>
int main()
{
int a = 0;
printf(" pid of ori is %d\n\n",getpid());
pid_t pid = fork();
if(pid == 0)
{
a+=9;
fflush(stdout);
printf("this is child,and a in child is %d\n",a);
printf("parent pid of child is %d\n \n\n\n\n",getppid());
fflush(stdout);
while(1);
}
else
{
a++;
fflush(stdout);
printf("this is father getpid %d\n",getpid());
printf("pid returned to father is %d\n",pid);
printf("parent pid is %d\n",getppid());
printf("this is father,and a in father is %d\n \n\n\n\n",a);
fflush(stdout);
while(1);
}
exit(0);
}
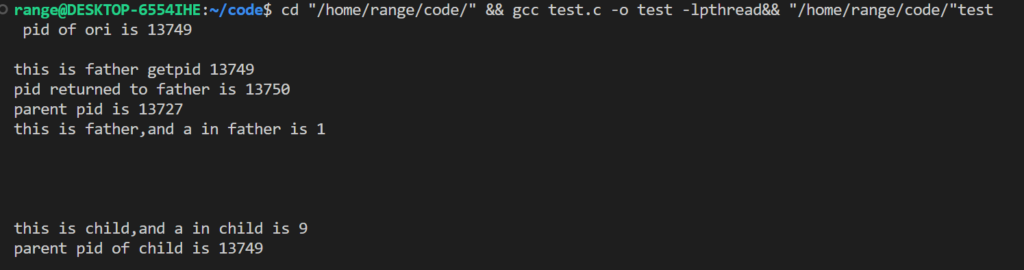
第一个,当一个进程调用fork的时候,它会新建一个和父进程几乎一样的进程(废话)。虽然你在终端只能看到一个输出(实际是共享了stdout,也就是共享了文件),但是确实同时存在两个进程(废话X2)。其中,原来的进程还是父进程,新建的子进程和父进程共享代码段,可以理解成共享代码逻辑和执行部分,剩下的变量等等是不共享的,系统会新搞出来新内存给子进程。比如我们的a值是不一样的,子进程的a也不是10,是9
另外,拷贝的子进程是从紧跟着fork();的后面执行的。可以粗暴的认为不是从头开始拷贝一个父进程,它连创建子进程时父进程的执行状态都拷贝了一遍,比如执行流就像拷贝了sp寄存器。所以,你可以认为一把叉子是一个执行流,父进程本来就是叉子柄,当执行fork时,开始分叉,父进程和子进程都变成了叉子的,,,尖。

配合proc和输出结果来看父进程为13749,父进程的父进程为13727,子进程为13750。
然后我们kill 13749试试。

如果你在这个时候kill掉父进程,子进程13750还在,会继续运行。但是因为每个进程都得有父进程,这时候没有父进程的子进程就会变成孤儿,被inti回收。init比较特殊。这也像叉子,每个尖尖都是独立的,然后每一个尖尖都有自己的柄,也就是父进程。
第二个,相信你应该一上来就被一些资料的“fork函数执行一次有两个返回值”这句话怼脸上。其实简单说,就是fork这个函数分别给父进程和子进程不同的返回值。给父进程返回的是子进程的PID,给子进程返回0.当然,如果返回负数那肯定是炸掉了。想想也是可以理解的,如果不返回两次,两个进程应该咋办,两个进程怎么区分谁是谁的爹?
最后从实用的角度来说,fork可以新建一个子进程,而通过这个if-else就能判断谁是子进程谁是父进程,帮助程序员写程序。再多提醒一下,不管是创建了几级的子进程,家业新兴也好四世同堂也好,fork给任何被创建的子进程都返回0.
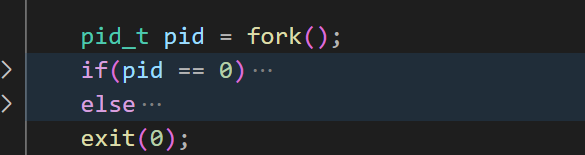
直接看看fork返回的是不是0就行了,不过按理说得判断是否小于0 的,这里我懒得写了。
注意,前文已经提到是子进程紧挨着fork后执行,所以这个判断是子进程和父进程都执行判断了。
还有一个知识点是进程图。详细可以参考csapp。不过了解原理和具体进行就不是难事了。
———————–补充———————————–
以下是给高阶选手阅读和讨论的,更多可以参考Linux内核的设计与实现。
1.Linux是怎样储存task_struct的?
2.Linux是怎样区分parents和siblings的?有没有办法从一个进程遍历Linux所有的进程?
3.Linux是怎么样做到高效写时复制的?这和虚拟内存有什么联系?
4.既然我们讲到了进程,那么线程又是怎样解决的?
5.我们可以做到创建多个进程,但是从我们的结果来看,我们不能确定进程的执行顺序。如果我们要自己实现一个shell(那个lab还没写,太痛啦),实现前台后台和特定顺序的执行,我们应该怎么做?
6.进程之间怎么沟通?难道kill命令就是字面上的kill吗?
7.以后需要fork的时候还会内心os F**K吗?
Views: 278
By newbing:
博客的补充环节提出了一些高级问题,涉及Linux内核的设计与实现。以下是对这些问题的简要回答:
Linux的task_struct存储: Linux使用task_struct结构体来存储进程信息,它包含了进程状态、堆栈、调度信息等。
区分parents和siblings: 每个进程在其task_struct中有指向父进程和兄弟进程的指针。通过这些指针,可以遍历进程树。
写时复制的高效实现: 写时复制(Copy-On-Write, COW)是通过虚拟内存管理实现的。当进程被复制时,它们共享相同的物理内存页面,直到其中一个进程尝试修改数据,此时会创建一个新的页面副本。
线程的处理: 线程在Linux中以轻量级进程(Lightweight Process, LWP)的形式实现,共享相同的地址空间但拥有独立的执行流。
控制进程执行顺序: 为了控制进程的执行顺序,可以使用进程间通信(IPC)机制,如信号量、消息队列和共享内存。shell的前台后台任务管理通常涉及信号和作业控制。
进程间通信: 进程间通信不仅限于kill命令。还有管道、信号、共享内存、信号量等多种方式。
fork的心理准备: 理解fork的工作原理和它在进程创建中的作用,可以帮助开发者更好地使用它,而不是感到困惑。
这些问题的深入讨论可以参考《Linux内核的设计与实现》等专业书籍。如果您对这些话题有更多的兴趣或问题,欢迎继续探讨。