KL 散度
KL散度衡量的是两个分布p(x)和q(x)之间的相似程度,其定义如下
\(D\left ( {p\left ( {x} \right )||q\left ( {x} \right )} \right )\, =\, \sum {{p}_{X}}\left ( {x} \right )log\frac {{p}_{X}\left ( {x} \right )} {{q}_{X}(x)}\, =\, {E}_{pX}\left [ {log\frac {{p}_{X}(x)} {{q}_{X}(x)}} \right ] \)需要注意的是,log的底数决定了单位. 底数是2,单位是比特(bits);底数是e,单位是奈特(nats).
我们可以通过推断来反映信息缺失. 结果越不确定,随机变量越不可被预测,推断更不准确.
KL散度永远大于等于零. 当p(x)=q(x)时等于零.
KL散度具有不对称性,即D(p(x)||q(x))不等于D(q(x)||p(x)).
香农熵
香农熵是一个数学上颇为抽象的概念,在这里不妨把香农熵理解成某种特定信息的出现概率(离散随机事件的出现概率). 一个系统越是有序,香农熵就越低;反之,一个系统越是混乱,香农熵就越高. 香农熵也可以说是系统有序化程度的一个度量. 香农熵的定义式为:
\(H(X) = – \sum_{i=1}^n P(x_i) log_2 P(x_i) \)相比只能刻画数字离散程度的方差,香农熵的适用范围更广. 它只考虑各个变量出现的概率.
香农熵永远大于等于零. 当X是确定的时候,H(X)=0.
联合熵与条件熵
对于联合变量X,Y,我们定义联合熵为
\(H(X,Y)\, =\, -\sum _{x,y} {{p}_{X,Y}}\left ( {x,y} \right ){log}_{X,Y}\left ( {x,y} \right ) \)对于条件变量X|Y,我们定义条件熵为
\(H(X|Y)\, =\, -\sum _{x} {{p}_{X|Y}}\left ( {x|y} \right ){log}_{X|Y}\left ( {x|y} \right )\)条件熵H(X|Y)衡量了X的平均离散程度.
对于所有的y,我们有
\(H\left ( {X|Y} \right )=\sum _{y} {H\left ( {X|Y=y} \right )=-\sum _{x,y} {{p}_{X,Y}}log{p}_{X|Y}\left ( {x|y} \right )}\) \(H(X)\, -\, H(X|Y)\, =\, D({p}_{X,Y}(x,y)||{p}_{X}(x){p}_{Y}(y))\geq 0\)联合熵与条件熵有如下关系:
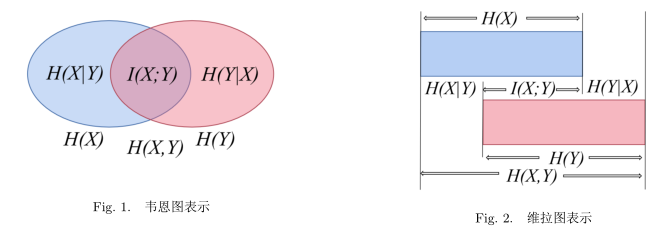
\(H\left ( {X,Y} \right )=H\left ( {X} \right )+H\left ( {Y|X} \right )=H\left ( {Y} \right )+H\left ( {X|Y} \right )\)平均互信息
平均互信息可以衡量两个变量的相关程度. 平均互信息可以看成是一个随机变量所包含的关于另外一个随机变量的信息量,或者是一个随机变量由于已知的另一个随机变量而减少的不确定性.
平均互信息用I(X;Y)表示:
\(I\left ( {X;Y} \right )=\sum _{X,Y} \left ( {} \right )p\left ( {x,y} \right )log\frac {p\left ( {x,y} \right )} {p\left ( {x} \right )p\left ( {y} \right )}\)此外,有
\(I\left ( {X;Y} \right )=H\left ( {X} \right )-H\left ( {X|Y} \right )=D(p\left ( {x,y} \right )||p\left ( {x} \right )p\left ( {y} \right ))\) \(I\left ( {Y;X} \right )=H\left ( {X} \right )+H\left ( {Y} \right )-H\left ( {X,Y} \right ).\)平均互信息有对称性。即I(X;Y)=I(Y;X).
当且仅当X与Y独立的时候有I(X;Y)=0. 反之亦然.
我们有I(X;X)=H(X).
我们可以使用韦恩图和维拉图来表示平均互信息:
Views: 143